Pseudocode for Invention Disclosures and Patent Applications
Jul 12th, 2022 by Dilworth IP | Recent News & Articles |
Use this link to view and download the infographic:
![]()

Some software and computer inventions can be difficult to describe with words and illustrations alone. This can make it challenging for inventors to disclose inventions to attorneys, and for attorneys to draft strong patents. Describing certain aspects of inventions with pseudocode can streamline the invention-disclosure process and ultimately improve patent quality.
Instead of relying on an inventor to translate complex processes and algorithms into words, an inventor can describe these processes and algorithms into informal technology-independent pseudocode, and then a competent attorney can translate this pseudocode into a description and claims of a patent application.
Pseudocode combines plain language with mathematical notation to capture the essential steps and complexity of a process or algorithm. There is no strict syntax, so it is important to control the appearance and organization of pseudocode to maximize human readability. Effective pseudocode uses basic structures like for-loops and function calls, and it usually resembles a well-known programming language in the relevant art.
This infographic highlights some best practices for pseudocode based on C, a well-known programming language in science and engineering. The text displayed on each microchip of the infographic describes the essentials of Appearance, Organization, Variables, Functions, and Operators (math, logic, and bitwise) for writing effective pseudocode.


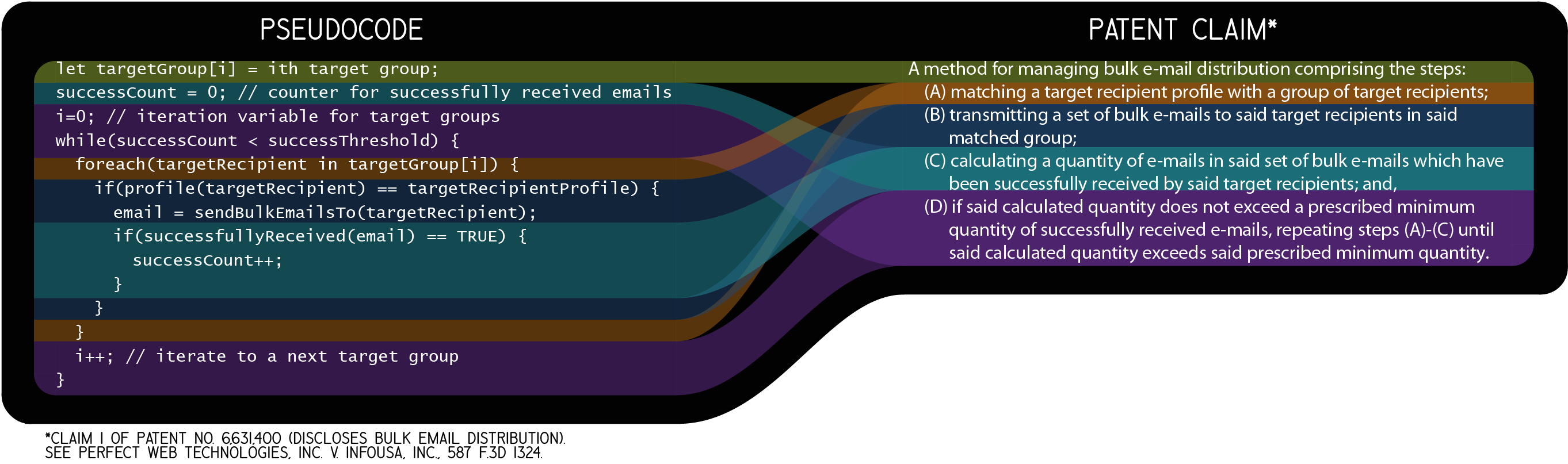
The bottom left of the infographic shows two snippets of pseudocode, and the bottom right shows equivalent independent claims, all of which are reproduced below. The colored bars show how the pseudocode maps to the limitations of the respective claims.
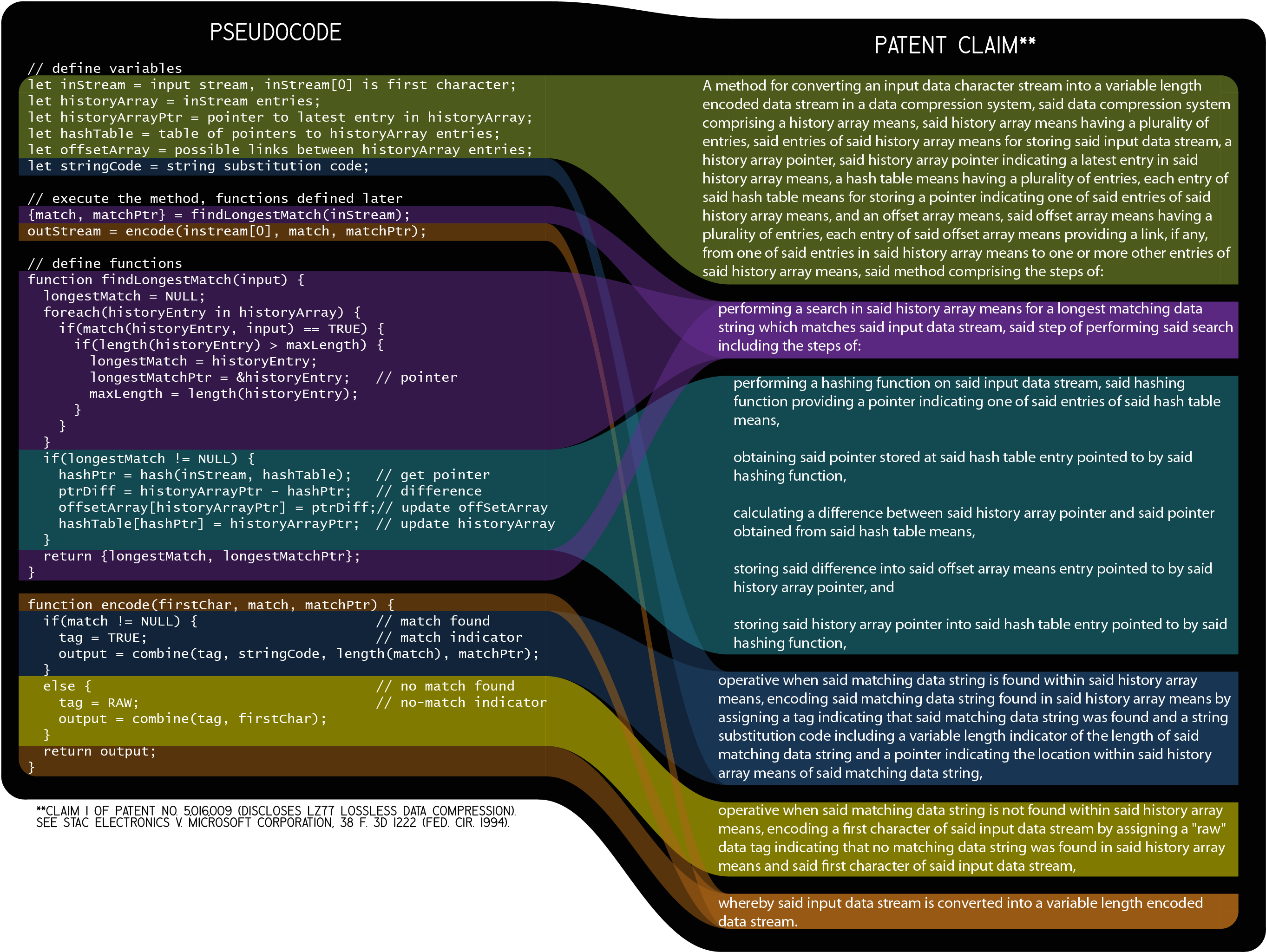
The variables and functions in pseudocode should be descriptively named so that a reader can infer something about what the variables represent and what the functions do. However, there is a tradeoff between the descriptiveness of a variable or function name and length of the variable or function name. For example, it is obvious that the variable historyArray in the second snippet above is an array of past values, but the name provides no information about the past values. The variable historyArray could have been named inStreamEntryHistoryArray because it is a history of input stream entries, but such a long name can be unwieldy to read and it may cause unsightly line wrapping. Instead, additional information about historyArray is given at the beginning of the snippet in an optional variables-declaration section.
Because there is no strict syntax in pseudocode, certain simplifying liberties can be taken. For example, the function findLongestMatch() in the second snippet above finds a longest match between the input stream (inStream) and an entry in the history array (historyEntry). However, the function findLongestMatch() only takes one argument (inStream). With strict syntax, both inStream and historyEntry would be global variables as the pseudocode is written, so technically neither would need to be passed to findLongestMatch() as arguments. Including inStream as an argument indicates to the reader that findLongestMatch() finds a longest match within inStream. While historyEntry might also be included as an argument, that would bring the foreach() loop outside of findLongestMatch() and therefore complicate the structure of the pseudocode—which is currently just two straightforward lines of code followed by function definitions that provide implementation details. By using functions in a main portion of a pseudocode snippet and providing implementation details elsewhere, the overall structure of an algorithm is usually more apparent to the reader.
While the syntax of pseudocode is flexible, the appearance and organization should be carefully controlled. After all, pseudocode is meant to be read by humans, not computers. In particular, using camelCase for variable and function names instead of hyphens or underscores increases legibility and reduces ambiguity, as does encapsulating levels of hierarchy with curly brackets while consistently indenting levels of hierarchy. Consider the following snippets that implement the same arbitrary algorithm. The left snippet—which lacks indentation, function parentheses, curly brackets, and camelCase—is not as easy to comprehend compared to the right snippet.

Pseudocode is a useful tool for invention disclosures for at least two reasons. First, many scientist- and engineer-inventors prefer writing code over writing prose. Empowering these inventors to communicate using their preferred methods can increase both the quality and quantity of invention disclosures. Simply put, inventors who dislike writing pages of prose may take shortcuts, or worse, avoid disclosing inventions altogether. Second, the code-like structure of pseudocode forces inventors to think critically about the discrete steps of an invention, including inputs, outputs, and specific processing that takes place. Pseudocode can therefore add concreteness to otherwise overgeneralized written descriptions.
To be clear, pseudocode is not a wholesale replacement for plain-language descriptions of inventions. In fact, prefacing pseudocode with a paragraph or two can add helpful context and can also simplify the pseudocode. For example, the number of nested levels of hierarchy in a snippet of pseudocode can be reduced by explaining with words that a following snippet only applies under certain conditions. In the following example, the left snippet includes several nested foreach() loops and an if() statement; the right snippet is prefaced with an explanation that the snippet only applies for certain conditions. The implementation details of the findLongestMatch() function in this example are omitted for brevity.

In summary, pseudocode is a tool that inventors can use to disclose certain aspects of inventions to patent attorneys, especially complex processes and algorithms in the software and computer arts. Following the simple guidelines highlighted in this article and in the infographic can streamline the invention-disclosure process and ultimately improve patent quality.
This article is for informational purposes, is not intended to constitute legal advice, and may be considered advertising under applicable state laws. The opinions expressed in this article are those of the author only and are not necessarily shared by Dilworth IP, its other attorneys, agents, or staff, or its clients.